
本文从消费者拉取消息开始分析消费流程,但kafka并不是单纯的在poll方法中拉取消息,鉴于消费者组的存在,以及Rebalance动作,使整个消费流程的复杂度直线上升,因此需要比生产者花费更多的章节去讲解
前文
本文首先解析消费者组协调者的初始化,先将poll方法中第一步看懂
coordinator初始化流程
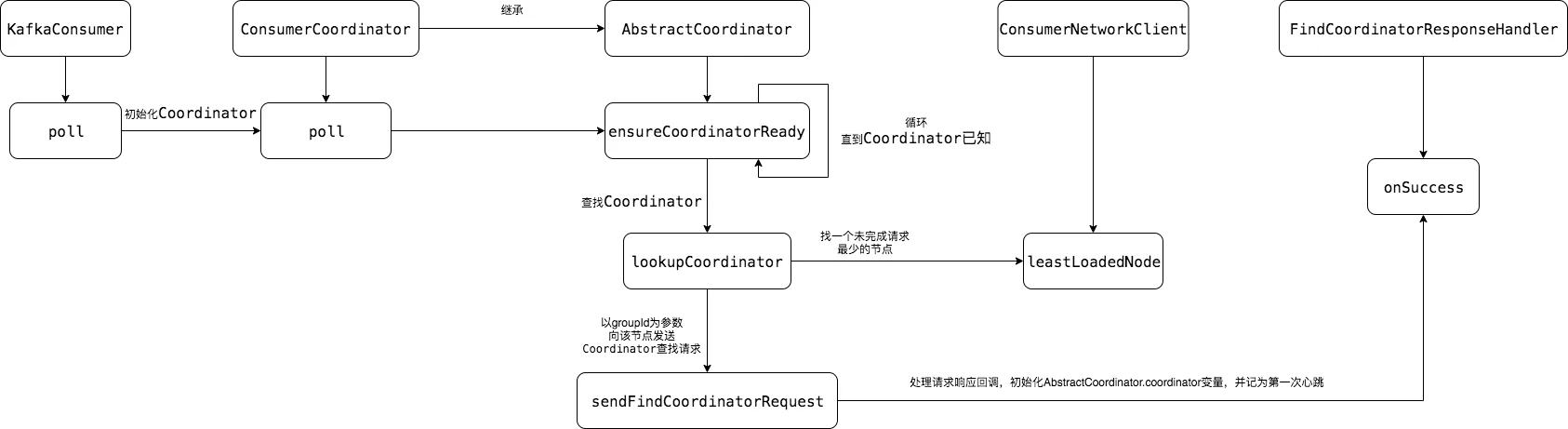
以上是coordinator初始化的流程,大致归纳为:以groupId为参数,向一个负载最小(未完成请求最少)的节点发送请求,成功之后初始化coordinator
源码
为了节省时间,将不是核心的部分代码省略
poll方法
源码如下,updateAssignmentMetadataIfNeeded方法coordinator初始化的入口
1 | private ConsumerRecords<K, V> poll(final long timeoutMs, final boolean includeMetadataInTimeout) { |
关于position
这里说的position是指TopicPartitionState的position属性,它记录上一次拉取的位移,
1 | private boolean updateFetchPositions(final long timeoutMs) { |
ConsumerCoordinator#poll方法
ensureCoordinatorReady1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60public boolean poll(final long timeoutMs) {
final long startTime = time.milliseconds();
long currentTime = startTime;
long elapsed = 0L;
invokeCompletedOffsetCommitCallbacks();
/**
* 是否手动制定了TP,else情况不再看了
*/
if (subscriptions.partitionsAutoAssigned()) {
// Always update the heartbeat last poll time so that the heartbeat thread does not leave the
// group proactively due to application inactivity even if (say) the coordinator cannot be found.
// 将消息拉取时间记为心跳线程最后一次拉取时间,那么说明是把消息拉取记为一次心跳
pollHeartbeat(currentTime);
// coordinator为null,连不上或者超时,触发ensureCoordinatorReady
if (coordinatorUnknown()) {
if (!ensureCoordinatorReady(remainingTimeAtLeastZero(timeoutMs, elapsed))) {
return false;
}
currentTime = time.milliseconds();
// elapsed 就是已用时间
elapsed = currentTime - startTime;
}
if (rejoinNeededOrPending()) {
// due to a race condition between the initial metadata fetch and the initial rebalance,
// we need to ensure that the metadata is fresh before joining initially. This ensures
// that we have matched the pattern against the cluster's topics at least once before joining.
if (subscriptions.hasPatternSubscription()) {
// For consumer group that uses pattern-based subscription, after a topic is created,
// any consumer that discovers the topic after metadata refresh can trigger rebalance
// across the entire consumer group. Multiple rebalances can be triggered after one topic
// creation if consumers refresh metadata at vastly different times. We can significantly
// reduce the number of rebalances caused by single topic creation by asking consumer to
// refresh metadata before re-joining the group as long as the refresh backoff time has
// passed.
if (this.metadata.timeToAllowUpdate(currentTime) == 0) {
this.metadata.requestUpdate();
}
if (!client.ensureFreshMetadata(remainingTimeAtLeastZero(timeoutMs, elapsed))) {
return false;
}
currentTime = time.milliseconds();
elapsed = currentTime - startTime;
}
if (!ensureActiveGroup(remainingTimeAtLeastZero(timeoutMs, elapsed))) {
return false;
}
currentTime = time.milliseconds();
}
}
maybeAutoCommitOffsetsAsync(currentTime);
return true;
}
ensureCoordinatorReady源码如下1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55protected synchronized boolean ensureCoordinatorReady(final long timeoutMs) {
final long startTimeMs = time.milliseconds();
long elapsedTime = 0L;
// 循环直至coordinator可用
while (coordinatorUnknown()) {
// 查找coordinator
final RequestFuture<Void> future = lookupCoordinator();
// 一直发生请求,直到future返回结果
client.poll(future, remainingTimeAtLeastZero(timeoutMs, elapsedTime));
if (!future.isDone()) {
// ran out of time
break;
}
// 处理失败
if (future.failed()) {
// 重试
if (future.isRetriable()) {
elapsedTime = time.milliseconds() - startTimeMs;
if (elapsedTime >= timeoutMs) break;
log.debug("Coordinator discovery failed, refreshing metadata");
client.awaitMetadataUpdate(remainingTimeAtLeastZero(timeoutMs, elapsedTime));
elapsedTime = time.milliseconds() - startTimeMs;
} else
throw future.exception();
} else if (coordinator != null && client.isUnavailable(coordinator)) {
// we found the coordinator, but the connection has failed, so mark
// it dead and backoff before retrying discovery
// 发现coordinator连不上,标记Coordinator未知,断开连接,之后进行重试
markCoordinatorUnknown();
final long sleepTime = Math.min(retryBackoffMs, remainingTimeAtLeastZero(timeoutMs, elapsedTime));
time.sleep(sleepTime);
elapsedTime += sleepTime;
}
}
return !coordinatorUnknown();
}
// 查找Coordinator,初始化了AbstractCoordinator.this.coordinator变量
protected synchronized RequestFuture<Void> lookupCoordinator() {
if (findCoordinatorFuture == null) {
// find a node to ask about the coordinator
// 找到当前未完成的请求最少的node
Node node = this.client.leastLoadedNode();
if (node == null) {
return RequestFuture.noBrokersAvailable();
} else
// 向该node发送Coordinator查询请求
findCoordinatorFuture = sendFindCoordinatorRequest(node);
}
return findCoordinatorFuture;
}
最小负载节点的计算
1 | public Node leastLoadedNode(long now) { |
Coordinator查询请求的处理
sendFindCoordinatorRequest使用底层的NetWorkClient发送请求,这里主要看响应结果处理1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34private class FindCoordinatorResponseHandler extends RequestFutureAdapter<ClientResponse, Void> { // 泛型表示handler的参数和返回值
public void onSuccess(ClientResponse resp, RequestFuture<Void> future) {
log.debug("Received FindCoordinator response {}", resp);
clearFindCoordinatorFuture();
FindCoordinatorResponse findCoordinatorResponse = (FindCoordinatorResponse) resp.responseBody();
Errors error = findCoordinatorResponse.error();
// 查询Coordinator响应结果处理
if (error == Errors.NONE) {
synchronized (AbstractCoordinator.this) {
// coordinatorConnectionId是计算出来的,而且是幂等的,感觉是个技巧性的代码
int coordinatorConnectionId = Integer.MAX_VALUE - findCoordinatorResponse.node().id();
// 初始化coordinator:connectionId,ip和端口
AbstractCoordinator.this.coordinator = new Node(
coordinatorConnectionId,
findCoordinatorResponse.node().host(),
findCoordinatorResponse.node().port());
log.info("Discovered group coordinator {}", coordinator);
// 这里应该是向coordinator所在的机器的Acceptor发送OP_CONNECT请求了
client.tryConnect(coordinator);
// 链接成功,相当于一次heartbeat
heartbeat.resetTimeouts(time.milliseconds());
}
future.complete(null);
}
}
public void onFailure(RuntimeException e, RequestFuture<Void> future) {
//清空引用,抛出异常...
}
}

